批量处理
本文提供了关于在多个文件上运行 OCRmyPDF 或将其配置为由文件系统事件触发的服务的信息。
批量作业
考虑使用出色的 GNU Parallel 一次性将 OCRmyPDF 应用于多个文件。
Both parallel 和 ocrmypdf 都会尝试使用所有可用的处理器。为了最大限度地提高并行性,同时又不因进程过多而使系统过载,可以考虑使用 parallel -j 2 将 parallel 限制为一次运行两个作业。
此命令将对当前目录中所有名为 *.pdf 的文件运行 ocrmypdf,并将结果写入之前创建的 output/ 文件夹。它不会搜索子目录。
--tag 参数告诉 parallel 在打印消息时将文件名作为前缀,这样就可以追溯任何错误到生成它们的文件。
parallel --tag -j 2 ocrmypdf '{}' 'output/{}' ::: *.pdf
OCRmyPDF 会在解析和从中收集信息之前自动修复 PDF。
目录树
这将遍历目录树,对所有文件进行就地 OCR 处理,并在每次运行时打印文件名
find . -name '*.pdf' -printf '%p\n' -exec ocrmypdf '{}' '{}' \;
这只会一次运行一个 ocrmypdf 进程。此变体使用 find 创建目录列表,并使用 parallel 并行运行 ocrmypdf,同样是就地更新文件。
find . -name '*.pdf' | parallel --tag -j 2 ocrmypdf '{}' '{}'
在 Windows 批处理文件中,使用
for /r %%f in (*.pdf) do ocrmypdf %%f %%f
使用 Docker 容器时,您需要通过标准输入和输出来进行流处理
find . -name '*.pdf' -print0 | xargs -0 | while read pdf; do
pdfout=$(mktemp)
docker run --rm -i jbarlow83/ocrmypdf - - <$pdf >$pdfout && cp $pdfout $pdf
done
示例脚本
这个用户贡献的脚本也提供了一个批量处理的示例。
#!/usr/bin/env python3
# SPDX-FileCopyrightText: 2016 findingorder <https://github.com/findingorder>
# SPDX-FileCopyrightText: 2024 nilsro <https://github.com/nilsro>
# SPDX-License-Identifier: MIT
"""Example of using ocrmypdf as a library in a script.
This script will recursively search a directory for PDF files and run OCR on
them. It will log the results. It runs OCR on every file, even if it already
has text. OCRmyPDF will detect files that already have text.
You should edit this script to meet your needs.
"""
from __future__ import annotations
import filecmp
import logging
import os
import posixpath
import shutil
import sys
from pathlib import Path
import ocrmypdf
# pylint: disable=logging-format-interpolation
# pylint: disable=logging-not-lazy
def filecompare(a, b):
try:
return filecmp.cmp(a, b, shallow=True)
except FileNotFoundError:
return False
script_dir = Path(__file__).parent
# set archive_dir to a path for backup original documents. Leave empty if not required.
archive_dir = "/pdfbak"
if len(sys.argv) > 1:
start_dir = Path(sys.argv[1])
else:
start_dir = Path(".")
if len(sys.argv) > 2:
log_file = Path(sys.argv[2])
else:
log_file = script_dir.with_name("ocr-tree.log")
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s %(message)s",
filename=log_file,
filemode="a",
)
logging.info(f"Start directory {start_dir}")
ocrmypdf.configure_logging(ocrmypdf.Verbosity.default)
for filename in start_dir.glob("**/*.pdf"):
logging.info(f"Processing {filename}")
if ocrmypdf.pdfa.file_claims_pdfa(filename)["pass"]:
logging.info("Skipped document because it already contained text")
else:
archive_filename = archive_dir + str(filename)
if len(archive_dir) > 0 and not filecompare(filename, archive_filename):
logging.info(f"Archiving document to {archive_filename}")
try:
shutil.copy2(filename, posixpath.dirname(archive_filename))
except OSError:
os.makedirs(posixpath.dirname(archive_filename))
shutil.copy2(filename, posixpath.dirname(archive_filename))
try:
result = ocrmypdf.ocr(filename, filename, deskew=True)
logging.info(result)
except ocrmypdf.exceptions.EncryptedPdfError:
logging.info("Skipped document because it is encrypted")
except ocrmypdf.exceptions.PriorOcrFoundError:
logging.info("Skipped document because it already contained text")
except ocrmypdf.exceptions.DigitalSignatureError:
logging.info("Skipped document because it has a digital signature")
except ocrmypdf.exceptions.TaggedPDFError:
logging.info(
"Skipped document because it does not need ocr as it is tagged"
)
except Exception:
logging.error("Unhandled error occured")
logging.info("OCR complete")
Synology DiskStation
如果安装了 Synology Docker 软件包,Synology DiskStation(网络连接存储设备)可以运行 OCRmyPDF 的 Docker 镜像。随附一个脚本,用于解决在这些设备上使用 OCRmyPDF 的一些特殊怪癖。
编写此脚本时,它仅适用于基于 x86 的 Synology 产品。目前尚不清楚它是否适用于基于 ARM 的 Synology 产品。可能需要进一步调整以应对 Synology 相对有限的 CPU 和 RAM。
#!/bin/env python3
# SPDX-FileCopyrightText: 2017 Enantiomerie
# SPDX-License-Identifier: MIT
"""Example OCRmyPDF for Synology NAS."""
from __future__ import annotations
# This script must be edited to meet your needs.
import logging
import os
import shutil
import subprocess
import sys
import time
# pylint: disable=logging-format-interpolation
# pylint: disable=logging-not-lazy
script_dir = os.path.dirname(os.path.realpath(__file__))
timestamp = time.strftime("%Y-%m-%d-%H%M_")
log_file = script_dir + '/' + timestamp + 'ocrmypdf.log'
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s %(message)s',
filename=log_file,
filemode='w',
)
start_dir = sys.argv[1] if len(sys.argv) > 1 else '.'
for dir_name, _subdirs, file_list in os.walk(start_dir):
logging.info(dir_name)
os.chdir(dir_name)
for filename in file_list:
file_stem, file_ext = os.path.splitext(filename)
if file_ext != '.pdf':
continue
full_path = os.path.join(dir_name, filename)
timestamp_ocr = time.strftime("%Y-%m-%d-%H%M_OCR_")
filename_ocr = timestamp_ocr + file_stem + '.pdf'
# create string for pdf processing
# the script is processed as root user via chron
cmd = [
'docker',
'run',
'--rm',
'-i',
'jbarlow83/ocrmypdf',
'--deskew',
'-',
'-',
]
logging.info(cmd)
full_path_ocr = os.path.join(dir_name, filename_ocr)
with (
open(filename, 'rb') as input_file,
open(full_path_ocr, 'wb') as output_file,
):
proc = subprocess.run(
cmd,
stdin=input_file,
stdout=output_file,
stderr=subprocess.PIPE,
check=False,
text=True,
errors='ignore',
)
logging.info(proc.stderr)
os.chmod(full_path_ocr, 0o664)
os.chmod(full_path, 0o664)
full_path_ocr_archive = sys.argv[2]
full_path_archive = sys.argv[2] + '/no_ocr'
shutil.move(full_path_ocr, full_path_ocr_archive)
shutil.move(full_path, full_path_archive)
logging.info('Finished.\n')
海量批量作业
如果您有数千个文件需要处理,请联系作者。与 OCRmyPDF 相关的咨询工作有助于资助这个开源项目,我们感谢所有的咨询。
热(监控)文件夹
使用 watcher.py 监控文件夹
OCRmyPDF 有一个名为 watcher.py 的文件夹监控器,目前包含在源代码分发中,但不属于主程序的一部分。它可以在本地使用,也可以在 Docker 容器中运行。本地实例通常提供更好的性能。watcher.py 适用于所有平台。
用户可能需要自定义脚本以满足其需求。
pip3 install ocrmypdf[watcher]
env OCR_INPUT_DIRECTORY=/mnt/input-pdfs \
OCR_OUTPUT_DIRECTORY=/mnt/output-pdfs \
OCR_OUTPUT_DIRECTORY_YEAR_MONTH=1 \
python3 watcher.py
环境变量 |
描述 |
|---|---|
OCR_INPUT_DIRECTORY |
设置要监控的输入目录(递归) |
OCR_OUTPUT_DIRECTORY |
设置输出目录(不应位于输入目录下) |
OCR_ARCHIVE_DIRECTORY |
设置已处理原始文件的存档目录(不应位于输入目录下,需要设置 |
OCR_ON_SUCCESS_DELETE |
如果退出代码为 0 (OK),这将把处理过的原始文件移动到 |
OCR_OUTPUT_DIRECTORY_YEAR_MONTH |
这将把文件放在输出目录下的 |
OCR_DESKEW |
对歪斜的输入 PDF 应用去歪斜处理 |
OCR_JSON_SETTINGS |
一个 JSON 字符串,指定 |
OCR_POLL_NEW_FILE_SECONDS |
轮询间隔 |
OCR_LOGLEVEL |
要显示的日志消息级别 |
可以将网络扫描仪或扫描计算机配置为将文件放入监控文件夹中。
使用 Docker 监控文件夹
watcher 服务包含在 OCRmyPDF Docker 镜像中。运行它的方法
docker run \
--volume <path to files to convert>:/input \
--volume <path to store results>:/output \
--volume <path to store processed originals>:/processed \
--env OCR_OUTPUT_DIRECTORY_YEAR_MONTH=1 \
--env OCR_ON_SUCCESS_ARCHIVE=1 \
--env OCR_DESKEW=1 \
--env PYTHONUNBUFFERED=1 \
--interactive --tty --entrypoint python3 \
jbarlow83/ocrmypdf \
watcher.py
此服务将监控匹配 /input/\*.pdf 的文件,将其转换为 /output/ 中的 OCR PDF,并将已处理的原始文件移动到 /processed。此镜像的参数有
参数 |
描述 |
|---|---|
|
放置在此位置的文件将进行 OCR 处理 |
|
这是存储 OCR 文件的位置 |
|
在此处存档已处理的原始文件 |
|
定义环境变量 |
|
定义环境变量 |
|
定义环境变量 |
|
这将强制 |
此服务依赖轮询来检查文件系统的更改。它可能不适用于某些环境,例如在慢速网络上共享的文件系统。
可以使用配置管理器(例如 Docker Compose)来确保服务始终可用。
# SPDX-FileCopyrightText: 2022 James R. Barlow
# SPDX-License-Identifier: MIT
---
version: "3.3"
services:
ocrmypdf:
restart: always
container_name: ocrmypdf
image: jbarlow83/ocrmypdf
volumes:
- "/media/scan:/input"
- "/mnt/scan:/output"
environment:
- OCR_OUTPUT_DIRECTORY_YEAR_MONTH=0
user: "<SET TO YOUR USER ID>:<SET TO YOUR GROUP ID>"
entrypoint: python3
command: watcher.py
注意事项
watchmedo在网络文件系统上可能无法正常工作,具体取决于文件系统客户端和服务器的能力。这个简单的方案不会过滤文件系统事件的类型,因此文件复制、删除、移动以及目录操作都将发送给 ocrmypdf,在某些情况下会产生错误。如果您除了向监控文件夹复制文件之外还进行其他操作,请禁用您的监控文件夹。
如果源目录和目标目录相同,watchmedo 可能会产生一个无限循环。
在 BSD、FreeBSD 和较旧版本的 macOS 上,您可能需要增加文件描述符的数量以监控更多文件,使用
ulimit -n 1024可以监控最多 1024 个文件的文件夹。
替代方案
在 Linux 上,可以配置 systemd 用户服务以自动对文件集合执行 OCR。
Watchman 是
watchmedo更强大的替代方案。
macOS Automator
您可以在 macOS 上使用 Automator 应用创建工作流程或快速操作。在工作流程中使用“运行 Shell 脚本”操作。在 Automator 的上下文中,PATH 的设置可能与您的终端的 PATH 不同;您可能需要显式设置 PATH 以包含 ocrmypdf。以下示例可作为起点
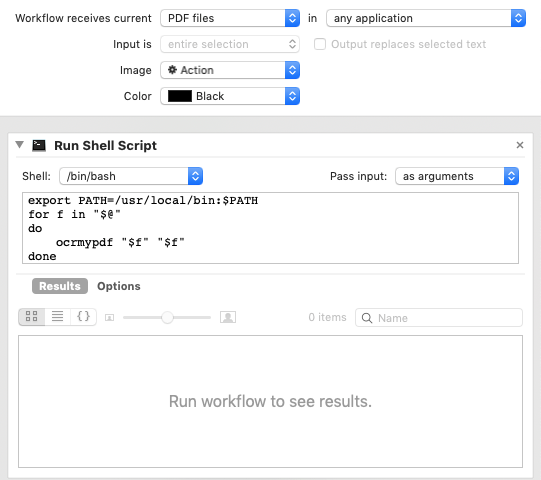
您可以自定义发送给 ocrmypdf 的命令。